







前編で紹介したように、2022年にメタバースの利用は大きく動き出し、「創造性」の観点からプロアマを問わないクリエイターたちの賛同が集まっている。しかし、生成AIの登場は今後のクリエイションに衝撃を与える可能性がある。後編となる本コラムでは、3Dモデルの工程に沿って生成AIの活用例を紹介したのちに、メタバース×生成AIの将来を展望する。
原義のメタバースシリーズ 第2回:メタバース×生成AI(後編)
(生成AIで)テキストからモノを作る時代へ
タグから探す
2023.11.14

生成AIによって変化する3Dモデルの製作工程
前編では、VR・メタバースによってユーザーは自由に創作する場を得たものの、技術的・知識的ハードルが高いことに言及した。実際に、先行して創作を開始したクリエイターを追って、オーディエンスからメタバース上のクリエイターへの転身を図るユーザーも多いと思われるが、そこで創作活動のハードルの高さを実感することも多いのではないだろうか。しかし生成AIの登場がその敷居を一気に下げる可能性がある。メタバースのクリエイターにとって、生成AIは衝撃的なイノベーションなのである。ここからは、前編で紹介した3Dモデルの基本的な製作工程(A.準備・構想、B.モデリング、C.マテリアル設定)に沿って、生成AIの活用事例を紹介し、メタバース×生成AIの将来を考えてみたい。
A.準備・構想
準備・構想では、参考情報の収集、アイデアの整理などを行う。必須の工程ではないが、製作対象の規模が大きくなる、もしくは複雑になるほどに重要性が増す。従来は、部分的に近い要素をもつ画像をデスクトップリサーチで集めたり、イラスト・写真など手作業でイメージを具体化させたりする必要があった。大規模なメタバースになるほど、この作業を繰り返す労力は多大である。
この工程では、「Stable Diffusion(Stability AI)」などの画像生成AIを用いて、テキストから参考画像などを生成することが可能になった(text-to-image, txt2img)。主な用途は、①コンセプトアート作成、②下絵作成である。
①コンセプトアート作成:「抽象的な段階で完成像の要素を書き起こしてtxt2imgで画像を出力する」工程であり、画像生成AIはイメージを膨らませる「壁打ち相手」の役割が期待される。出力結果は直接的に利用されることはなく、あくまでイメージを具体化させるための素材である。
②下絵作成:「ある程度具体的な完成像に基づいて、要件を満たす画像を得る」工程であり、イメージを収束させることが画像生成AIの役割として期待される。出力結果は、後続のモデリング工程において、下絵として直接利用される可能性がある。
この工程では、「Stable Diffusion(Stability AI)」などの画像生成AIを用いて、テキストから参考画像などを生成することが可能になった(text-to-image, txt2img)。主な用途は、①コンセプトアート作成、②下絵作成である。
①コンセプトアート作成:「抽象的な段階で完成像の要素を書き起こしてtxt2imgで画像を出力する」工程であり、画像生成AIはイメージを膨らませる「壁打ち相手」の役割が期待される。出力結果は直接的に利用されることはなく、あくまでイメージを具体化させるための素材である。
②下絵作成:「ある程度具体的な完成像に基づいて、要件を満たす画像を得る」工程であり、イメージを収束させることが画像生成AIの役割として期待される。出力結果は、後続のモデリング工程において、下絵として直接利用される可能性がある。
図表1 画像生成AIによる生成結果
左:車のコンセプトアート風、右:アバターのモデリングに用いる下絵風
左:車のコンセプトアート風、右:アバターのモデリングに用いる下絵風

出所:三菱総合研究所
図表1はStable Diffusionを用いてtxt2imgで生成した画像である。左図はコンセプトアート作成、右図はアバターのモデリングを想定した出力である。アバターを作成する場合、イメージした視覚的要素をテキストに書き起こして生成AIに入力することで、短時間で大量の参考画像を簡単に生成することができる。ただしイメージしている内容と利用するモデルの学習データセットに乖離がある場合には、コンセプトアートを作成するために、試行錯誤が必要になる場合がある。独創性が強いアイデアになるほど、その度合いは大きくなる。そのため、イメージが抽象的な段階で画像生成を試みて、画像生成AIの生成画像に対して要素を足し引きしながら、イメージを具体化するといった活用方法が、現時点では最も有効と考えられる。
B.モデリング
モデリングの工程では、3Dモデルの形状を作る。モデリングツールを用いた作業であり、点、線、面で形状を作る3DCAD的なアプローチ、スカルプティングと呼ばれる彫刻的アプローチなど複数の方法があり、最終的には面で囲まれた立体を得ることができる。アバターの場合には、作成した3Dモデルに「リグ(モデリングした物体を動かす仕組み)と呼ばれる骨を通して、リグの動きに応じて周囲の面(骨になぞらえるならば筋肉や皮膚など)を変形させ体の動きを表現する。
近年は、テキストや画像から直接3Dモデルを生成するAI(Text-to-3D)の開発が進められている。著名なサービスとして2022年9月に発表された「DreamFusion※1」がある。DreamFusionの詳細な技術的解説は本コラムの趣旨に外れるため割愛するが、2D画像でトレーニングされた拡散モデルを用いて、図表2のような3Dモデルを生成することが可能である。
近年は、テキストや画像から直接3Dモデルを生成するAI(Text-to-3D)の開発が進められている。著名なサービスとして2022年9月に発表された「DreamFusion※1」がある。DreamFusionの詳細な技術的解説は本コラムの趣旨に外れるため割愛するが、2D画像でトレーニングされた拡散モデルを用いて、図表2のような3Dモデルを生成することが可能である。
図表2 DreamFusionで生成された3Dモデル

出所:DreamFusion:Text-to-3D using 2D Diffusion, Ben Poole et al.,
https://arxiv.org/pdf/2209.14988.pdf(閲覧日:2023年11月1日)
https://arxiv.org/
その一方で、DreamFusionを利用した3Dモデルの生成には時間を要すると報告されている※2。また、生成結果も修正せずに利用できるほど精度が高いとは言えない。そのため、実務に利用する場合は、人間による修正が必要であり、2023年6月現在、人手でモデリングする方が一般的といえる。ただしこれは、2023年6月時点の実態であり、今後、短時間で精度の高い生成結果が得られるようになれば、画像生成と同様に専門的なツールを使わずに目的の3Dモデルを作成できるようになるだろう。
C.マテリアル設定
この工程では、Bで作成した3Dモデルに質感、色味などの見た目の情報を設定する。マテリアルは主に、シェーダ(陰影処理)やテクスチャ(質感処理)で設定する。テクスチャは模様や柄などの情報を設定するために利用するが、従来はインターネットで公開されている素材や自分で撮影した画像、作成したイラストなどを用いていた。
画像生成AIには、Carson Katri 氏が開発した「Dream Textures」のように、モデリングソフト上でテクスチャ画像などを生成することに特化したアドオンが存在する。一般的な画像生成AIは、提供元や有志が開発したUIを介してプロンプトを入力し、生成結果を受け取ることが多い。Dream Texturesは、モデリングソフトである「Blender(Blender Foundation)」のアドオンとして提供されており、Blenderからウィンドウを切り替えることなく、テクスチャ画像を生成して作成中の3Dモデルのテクスチャとして設定することが可能である。
画像生成AIには、Carson Katri 氏が開発した「Dream Textures」のように、モデリングソフト上でテクスチャ画像などを生成することに特化したアドオンが存在する。一般的な画像生成AIは、提供元や有志が開発したUIを介してプロンプトを入力し、生成結果を受け取ることが多い。Dream Texturesは、モデリングソフトである「Blender(Blender Foundation)」のアドオンとして提供されており、Blenderからウィンドウを切り替えることなく、テクスチャ画像を生成して作成中の3Dモデルのテクスチャとして設定することが可能である。
図表3 Dream Texturesを用いたテクスチャ画像生成の流れ(左)と完成イメージ(右)
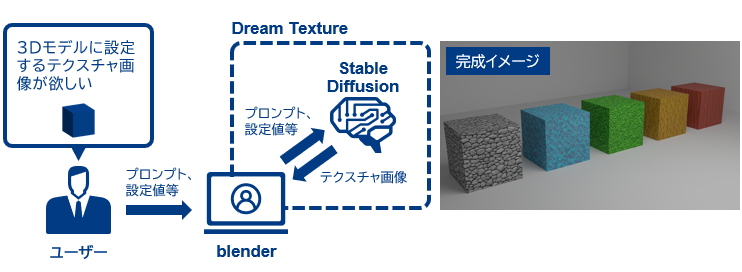
出所:三菱総合研究所
紹介したように3Dモデルの作成工程は、生成AIの進歩により部分的に自動化が可能になってきた。今後は生成AIの進化により、ルーティン的な工程は生成AIに任せる、もしくは生成結果を土台にして作業することで、クリエイターは創造的な工程に集中することが可能になるだろう。
メタバース×生成AIの将来
生成AIの登場により、専門的な知識や技術を必要とする従来の製作工程は簡略化が進んでいる。その一方で、現在の生成AIには著作権などの法律的な課題も存在する。画像生成AIにおいては、Hugging Face(Hugging Face, Inc.)などのサービスを通して、一般のユーザーが作成した追加学習済みモデルが公開されている。しかし、こうしたモデルの一部は学習データの不透明性が指摘されている。さらに複数の学習済みモデルをマージして、新たなモデルを作成している場合、そのプロセスが繰り返されるほどに元モデルの追跡も困難になる。これにより、法的な問題を抱えるモデルを起源にもつモデルをすべて特定し、対応することは著しく困難になることも予想される。
こうした背景から、Adobe Inc.のAdobe Fireflyなど、企業が提供する生成AIサービスの動向も注目されている。2023年6月8日にはAdobe Fireflyのエンタープライズ版が発表され、利用に伴う訴訟は同社が保証するとのコメントが添えられた。同製品はオープンライセンスの画像や著作権の失効したパブリックドメインの画像と、コントリビューターと呼ばれる提供者の画像を学習に利用しており、学習データの透明性を売りにしている。
このように、著作権の扱いなど、生成AIの活用についてはまだ議論がなされている段階である。また、生成AIを使った画像、3Dモデルを作るためのノウハウや技術の習得には相応のコストも必要となる。それでも、生成AIの出現と発展はメタバースでの創作ハードルを低減させることは間違いない。
メタバース×生成AIの組み合わせが、クリエイターの増加や交流の活発化、バーチャルエコノミーの発展を引き起こす——。筆者はそんな未来を想像している。
こうした背景から、Adobe Inc.のAdobe Fireflyなど、企業が提供する生成AIサービスの動向も注目されている。2023年6月8日にはAdobe Fireflyのエンタープライズ版が発表され、利用に伴う訴訟は同社が保証するとのコメントが添えられた。同製品はオープンライセンスの画像や著作権の失効したパブリックドメインの画像と、コントリビューターと呼ばれる提供者の画像を学習に利用しており、学習データの透明性を売りにしている。
このように、著作権の扱いなど、生成AIの活用についてはまだ議論がなされている段階である。また、生成AIを使った画像、3Dモデルを作るためのノウハウや技術の習得には相応のコストも必要となる。それでも、生成AIの出現と発展はメタバースでの創作ハードルを低減させることは間違いない。
メタバース×生成AIの組み合わせが、クリエイターの増加や交流の活発化、バーチャルエコノミーの発展を引き起こす——。筆者はそんな未来を想像している。
本コラムに第三者の商標が含まれている場合がありますが、当該商標の使用は本記事の出所を表すものではなく、名称として表示するものです。
※1:DreamFusion:Text-to-3D using 2D Diffusion, Ben Poole et al.,
https://arxiv.org/
※2:Googleが開発する機械学習に特化した専用プロセッサ「Tensor Processing Unit(TPU)」の第4世代モデル「TPU v4」で1.5時間程度と報告されている。また、近年では、従来と同程度の品質で高速な最適化を可能にするフレームワークも提案されつつある。
著者紹介
連載一覧
関連するナレッジ・コラム
-
 2023.12.1企業は生成AI活用で競争力強化を
2023.12.1企業は生成AI活用で競争力強化を -
 2023.12.1生成AIをめぐる世界の議論と日本の役割
2023.12.1生成AIをめぐる世界の議論と日本の役割 -
2023.11.15原義のメタバースシリーズ 第3回:メタバースサービスの構築
-
2023.11.14原義のメタバースシリーズ 第2回:メタバース×生成AI(前編)
-
2023.8.28原義のメタバースシリーズ 第1回:利用者の姿(後編)
-
2023.8.28原義のメタバースシリーズ 第1回:利用者の姿(前編)
-
 2023.3.30三菱総合研究所、国内のメタバースの認知・利用に関する研究成果を発表
2023.3.30三菱総合研究所、国内のメタバースの認知・利用に関する研究成果を発表 -
 2017.2.1デュアルユースでイノベーションの機会をつかむ
2017.2.1デュアルユースでイノベーションの機会をつかむ
もっと見る
閉じる
関連するセミナー
トレンドのサービス・ソリューション


ナレッジ・コラムに関するお問い合わせや、取材のお申し込み、
寄稿や講演の依頼などその他のお問い合わせにつきましても
フォームよりお問い合わせいただけます。
寄稿や講演の依頼などその他のお問い合わせにつきましても
フォームよりお問い合わせいただけます。