







第1回のコラムでは自然言語処理を概観し、文章生成技術として「テンプレート方式」「言語モデル方式」について触れた。本コラムでは、当社が扱っている「言語モデル方式」の文章生成AIを使用して、株式会社帝国データバンク※1と共同で行った実務適用を想定した検証について紹介する。
実用化が始まる文章生成AI 第2回:概要と企業信用調査レポート作成支援の検証
タグから探す
2020.6.15

言語モデル方式の文章生成AIの概要
当社が扱っている言語モデル方式の文章生成AIは、北京大学、株式会社天公システム※2と共同で開発したものである※3。第1回のコラムでも説明した通り、数値と文章のペアをもとに学習を行い、AIモデルを生成し、実務適用時は数値を入力すれば適切な文章を出力できるようになる(図1)。
図1 言語モデル方式
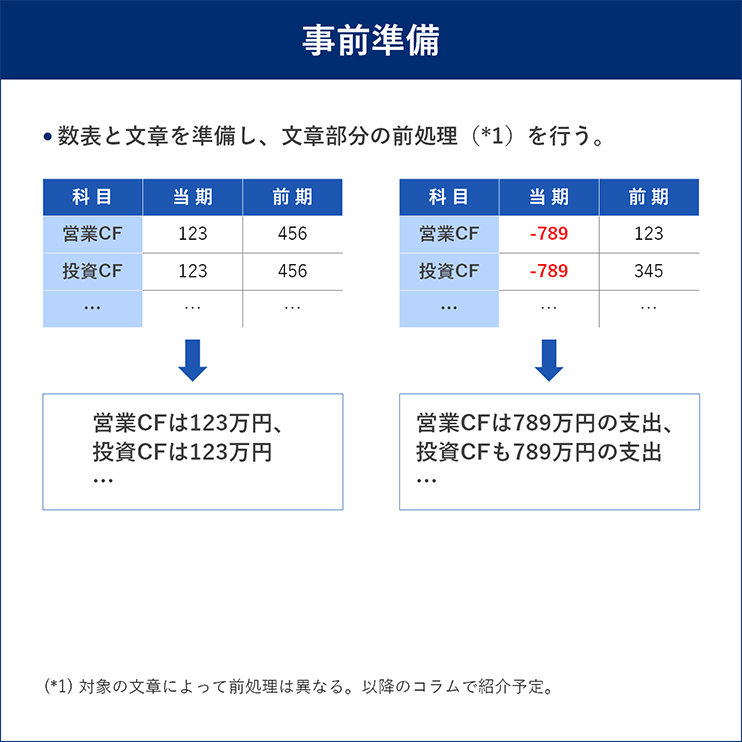
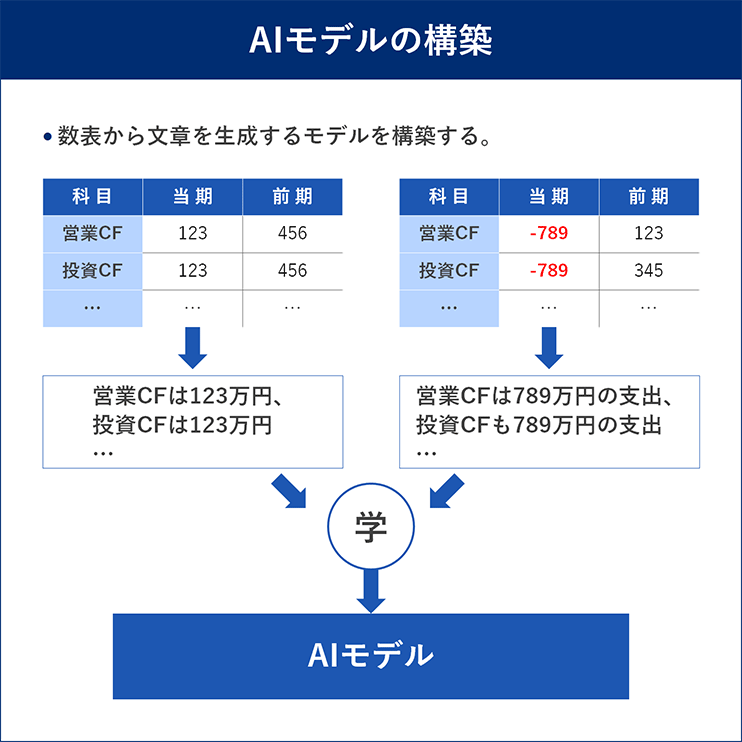
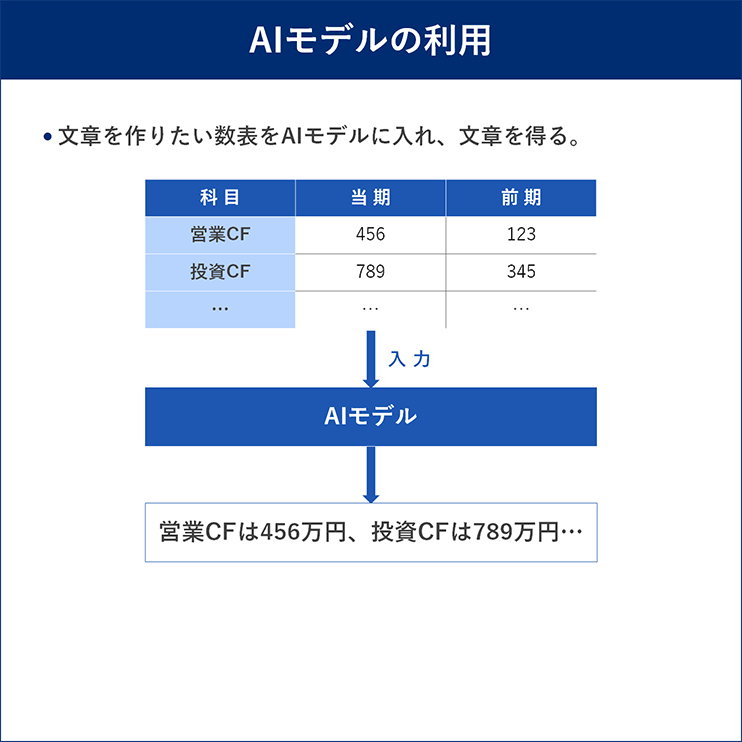
出所:三菱総合研究所
ここで留意しなければならないのは、AIが学習するのは定量部分※4ということである。数値データと業界の状況などを勘案した定性分析、例えば、マーケットに影響する大統領発言などの時事との関係を織り込むことは人にしかできない。そのため、文章生成AIはあくまで文章作成支援ツールであり、本AIを利用して文章を作成する場合、最終的には人が評価する業務フローを想定している(図2)。
図2 文章生成AIの業務適用イメージ
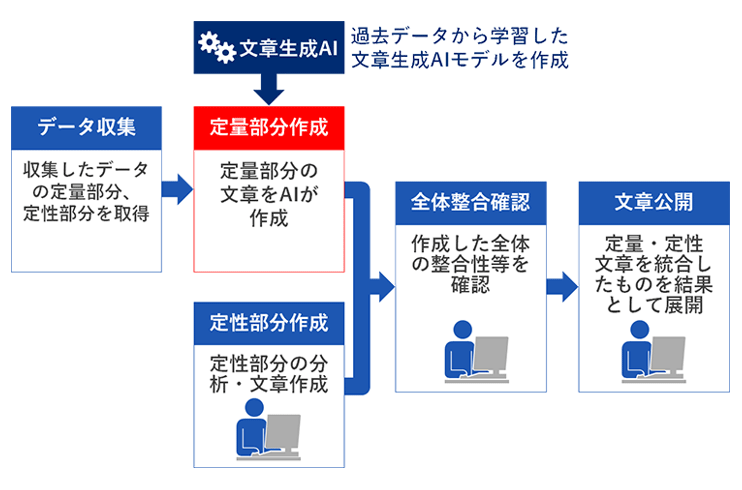
出所:三菱総合研究所
株式会社帝国データバンクとの検証の背景
株式会社帝国データバンク(以下TDB)は企業の信用調査を行っている企業であり、企業が新規取引をしたり、融資をする際などには、そのレポートが参照されている。レポートには各企業に対して行ったヒアリングや財務データなどの情報を統合した分析が表現されている。的確なレポートを作成するためには、該当企業が属する業界の動向、それまでの経緯や立地などの膨大な知見が必要であり、さらにそれらを文章に書き起こす能力が必要となる。また、レポートを作成する件数も膨大であることから、文章を一から書き起こすとトータルでは膨大な時間がかかる。そこで、レポートの定量部分については、文章生成AIを利用して過去の知見を反映した文章の下書きを出力し、人は分析と全体の取りまとめに専念することで全体の効率化を図るというユースケースを想定し、その実務適用の可能性について検証を実施した。
文章生成AIが生成した文章と評価結果
今回の検証では2回に分けてモデル作成を行った。
文章1モデル
文章2モデル
文章1モデル
- 初回実施となるため、文章全体を対象としたモデルを作成
- 文章に合わせてフラグ化した数値項目を追加
- 文章の長さなどの視点で発生頻度の低いものを除外 など
文章2モデル
- 文章1モデルの結果を受けて、観点ごとにモデルを作成
- 二つの観点についてそれぞれモデルを作成
- 数値から判断できる内容について学習用データの文章にフラグを追加 など
文章1、文章2はそれぞれのモデルが出力した文章例である。(※値は変更)
[文章1]
収支ともに現金100%の取引で、回収面では一部手形回収が含まれるため、支払先行の収支バランスとなっている。
平成□年△月期の運転資金分析では、棚卸資産回転期間0.1カ月、売上債権回転期間2カ月に対し、買入債務回転期間 XXXカ月と必要運転資金は2カ月分(500万円)となっている。
この資金需要には、金融機関からの借入金を織り交ぜての資金操作となっている。
回収面では、不良債権の発生はないようだ。
資金調達力については、平成□年△月期の返済原資(当期純利益+減価償却費ー社外流出額)は500万円を創出しており、返済能力は認められる。
また、社有不動産には担保設定がないことから担保余力は窺えないほか、有利子負債月商倍率は1.5倍と借入依存度は低位にあることから、運転資金程度の調達は可能と判断する。
[文章2]
回収は現金100%に対して、支払いは現金50%、手形50%であるが、回収サイトは最長60日と長いため、サイトバランスは支払いが先行している。
また、未成工事支出金など棚卸資産が月商の1.5カ月分程度あるため、月商の2カ月分程度の運転資金需要が発生しており、必要時には金融機関からの借入によって資金操作している。
以上の例では、文章1は一部変換ができていない(「XXX」部分)が、どちらも一見、日本語として不自然な部分はなく、読み進められる文章※5になっている。今回使用している文章生成AIでは学習用データが少ない場合でも、上記の通り日本語としての滑らかさが問題になることはあまりない。したがって、問題は「表現されている内容が正しいか?」※6「文章が正しいことをどのように評価するか?」である。文章1、2は、それぞれの問題に対応した結果出力されたものとなる。これらの文章の評価には業務知識が不可欠であるため、TDBの皆さまには多くのご協力をいただいた。文章1のモデルについての評価をまとめたものが図3である。
図3 文章1モデル評価結果(評価項目は一部抜粋)
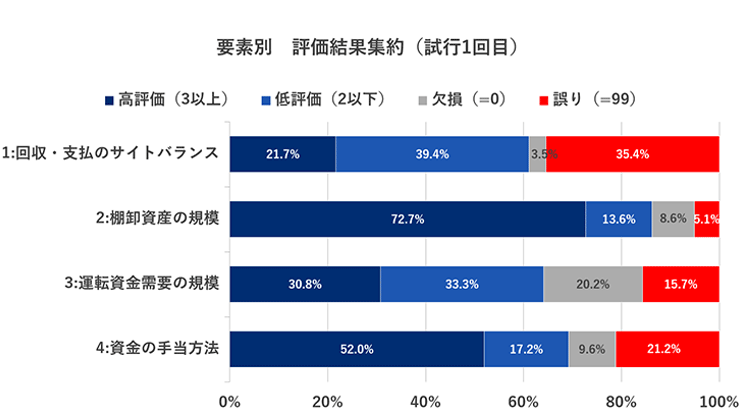
出所:三菱総合研究所
文章1モデルの特徴は、「回収・支払いのサイトバランス」など複数の観点を一度に生成できる点である。文章1のように一見問題ないように見えても、観点によっては数値との対応を見ると誤り(グラフの赤い部分)が多く含まれていることが分かる。また、出力した文章の中にはぎこちないものも存在した。主な指摘事項としては以下のようなものが含まれる。
- 結論が逆転している(必要運転資金があり、資金繰り逼迫に見える内容だが「余裕あり」とするなど)
- 観点を重複して説明している(サイトバランスについての文章を2回出力するなど)
- データから判別できない表現が存在する(社有不動産の有無を投入していないが担保に入れていると出力するなど)
図4 文章2モデル評価結果(評価項目は一部抜粋)
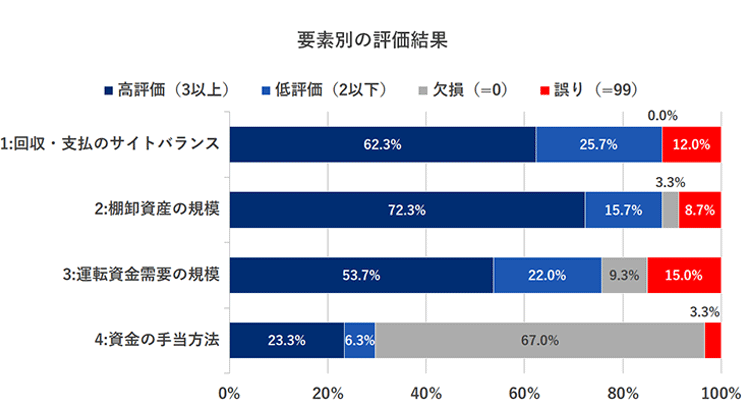
出所:三菱総合研究所
文章2の文章は観点ごとに作成した異なるモデル※8を使用している。文章1の評価と比較すると格段に誤りが減少しており、対象とした観点については高評価が約6割に達している。低評価部分の解消を含めた今後の課題として以下を認識している。
- ロジックの不整合、不自然な日本語※9への対応
- 表現した数値に対する説明の不足
- 学習用データ中の数値と文章の不整合の解消
文章生成AIのモデル構築作業と課題への対応
以降は、多くのAI関連プロジェクトで行い、今回の検証でも実施した泥臭い作業※10の内容について説明する。
今回の文章生成AIモデルの作成にあたり、レポートの中でAI支援の効果が一番高いと思われるセクション、効果がある業種を調整して、以下の手順で実施した。
今回の文章生成AIモデルの作成にあたり、レポートの中でAI支援の効果が一番高いと思われるセクション、効果がある業種を調整して、以下の手順で実施した。
基礎分析
対象のセクションの概要を把握するために形態素解析などの基礎分析を実施し、文章が以下の状態であることを把握した。
- 全形態素数のうち使用頻度の高いものは3割程度
- 定量的な内容の文は7割程度
事前準備
図1で紹介した「言語モデル方式」の概要にある通り、文章側の前処理を行う必要がある。具体的には図5にあるように元の文章を加工する作業となる。
図5 文章加工作業例

出所:三菱総合研究所
文章生成AIで出力したいのは具体的な数値ではなく、文章の流れとして出力すべき科目とその位置であるため、ここでは原文の数値を出力すべき科目などのタグに置換することを行っている。数値データは存在するので、機械的に出力できそうなものだが、実際にはさまざまな分析や最新の情報を反映しているため、単純にマッチングを行うだけでは置換できないケースが存在した。わかりやすいものとしては以下のようなものがあった。
- データを加工して利用している(財務諸表、財務分析にある値とヒアリング内容からより実態に近い値を求めているなど)
- 複数の科目が同一の数値を持っているケースがある(財務分析上のある回転率の値と同一の数値を持つ科目があるなど)
- 数値が丸められている(100万円単位で記載するなど)
モデル作成(文章1)
文章1ではこれらの要因を随時解消しながらモデルを作成していく方針を採った。解消していくことでモデルが出力する文章の精度は上がっていったが、最終的な評価は図3のとおり誤りが目立つ結果となった。
モデル作成(文章2)
文章1の評価、課題をもとに文章2では観点ごとにモデルを作成する方針とした。学習用データに対して数値をマッチングする対応を引き続き実施するとともに、数値データに新たなフラグを追加するなどの対応を行った。最終的な評価は図4のとおり、モデルを作成する対象とした観点1、2について誤りは大幅に減少し、高評価の割合も増加した。
評価方法(文章1、文章2共通)
文章生成AIが出力した文章の評価を機械的に実施することもある程度可能※11であるが、今回の試行では出力した文章を内容で評価※12する必要があるため、人による評価を実施した。
図6 評価シートイメージ
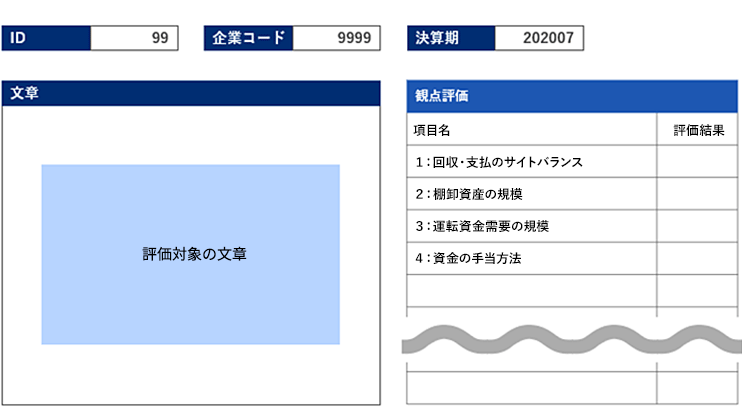
出所:三菱総合研究所
1件の文章を複数人で評価すること、多数の文章を評価することから図6にある評価シートを作成し、TDBの皆さまに多大な時間を割いて記入いただいた。
最後に
今回の検証で文章生成AIがレポート作成業務を支援するに足る精度の文章を生成するための方策が確認できたと考えている。今後、業務適用を実現するためには生成される文章の精度向上と合わせて、実際に現場で支援ツールとして使用する際に、どのような形・タイミングで出力するのが適切であるかを検討していく必要があると考えている。
謝辞
本検証においてはデータおよび業務知見の提供、評価の実施など数多くの方にご協力をいただいた。特に株式会社帝国データバンクのデータソリューション企画部と業務推進部の皆さまに厚く御礼を申し上げたい。
本検証においてはデータおよび業務知見の提供、評価の実施など数多くの方にご協力をいただいた。特に株式会社帝国データバンクのデータソリューション企画部と業務推進部の皆さまに厚く御礼を申し上げたい。
※ 1:株式会社帝国データバンク
http://www.tdb.co.jp/
※ 2:株式会社天公システム
http://www.pkutech.co.jp/(閲覧日:2020年6月2日)
※ 3:三菱総合研究所ニュースリリース「数表から文章を自動作成するAI技術を北京大学と共同開発」(2019年5月27日)
※ 4:ある程度の定性部分も出力することは可能であるが、時事や時流の分析が必要な文章は、事象を学習時にデータとして取り込むことができないので、出力される内容はもっともらしいが真実ではない。
※ 5:海外製品の日本語マニュアルに時々見られる、読む前から一見して文法がおかしい、係り受けが間違っているようなものとは品質が格段に異なる。
※ 6:GPT-2を使用したText Synth(http://textsynth.org/)のように文章を生成するAIはある。文章の自然さは優れているとの評価がされているが、今回のように入力されたデータに対しての正しさを求めることはできないため、少なくとも今回の業務で使用できるものではない。
※ 7:データを投入していない場合でも滑らかな表現となっており、中には妥当な表現も存在した。投入データに対する出力文章を検証することが目的であるため、妥当であっても、そのような文章を評価するのは適切ではなかった。
※ 8:観点1、観点2それぞれにフォーカスしてモデルを作成したが、学習時の文章には1文の中に複数の観点が含まれていることがあるため、出力の可能性がある4つの観点について評価を実施している。4つ目の観点について欠損が多くなっているのは上記の理由による。
※ 9:「支払いは現金100%60日、回収は現金100%30日となっているが、回収先行のサイトバランスとなっている。」のように、“が”でつなぐ必要はない。このように、一見問題ないが、読んでゆくと不自然なケースがあった。
※10:通常、作業の割合としてはこちらのほうが大きい。「泥臭い」というとネガティブなイメージになるが、この作業を通じてデータの内容や性質に関する知見が得られるので、「データを入れるだけで答えが出る」ようなツールは泥臭い作業をした後のデータが投入されることを暗喩していると信じている。
※11:Universal Sentence Encoderを用いた類似度など機械的な指標は、目安にはなるが評価として依存することはできない。長い文章で内容がほとんど一緒だが、最後だけ「である」「でない」という違いがあった場合、人であれば内容が逆であることが分かるが、機械的に評価すると高得点となるケースがある。
※12:本検証では学習時に用意した、数値データに対応する文章と同一のものを出力することが目的ではなく、数値データからから出力された文章の内容の適正さを評価することが目的であるため。
連載一覧
関連するナレッジ・コラム
-
 2024.2.1デジタルで社会の未来を切り拓く
2024.2.1デジタルで社会の未来を切り拓く -
 2024.2.1データ共有で医療介護インフラの変革を
2024.2.1データ共有で医療介護インフラの変革を -
 2024.1.30三菱総合研究所、非言語情報のデジタル化によるコミュニケーションの未来に関する研究成果を発表
2024.1.30三菱総合研究所、非言語情報のデジタル化によるコミュニケーションの未来に関する研究成果を発表 -
 2024.1.10人口減少時代、地域金融機関はどう変わるべき? 第2回
2024.1.10人口減少時代、地域金融機関はどう変わるべき? 第2回 -
2024.1.10人口減少時代、地域金融機関はどう変わるべき? 第1回
-
 2023.12.1企業は生成AI活用で競争力強化を
2023.12.1企業は生成AI活用で競争力強化を -
 2023.12.1生成AIをめぐる世界の議論と日本の役割
2023.12.1生成AIをめぐる世界の議論と日本の役割 -
 2023.12.1防災DXから生まれる新サービスの脈動
2023.12.1防災DXから生まれる新サービスの脈動
もっと見る
閉じる
関連するセミナー
トレンドのサービス・ソリューション


ナレッジ・コラムに関するお問い合わせや、取材のお申し込み、
寄稿や講演の依頼などその他のお問い合わせにつきましても
フォームよりお問い合わせいただけます。
寄稿や講演の依頼などその他のお問い合わせにつきましても
フォームよりお問い合わせいただけます。