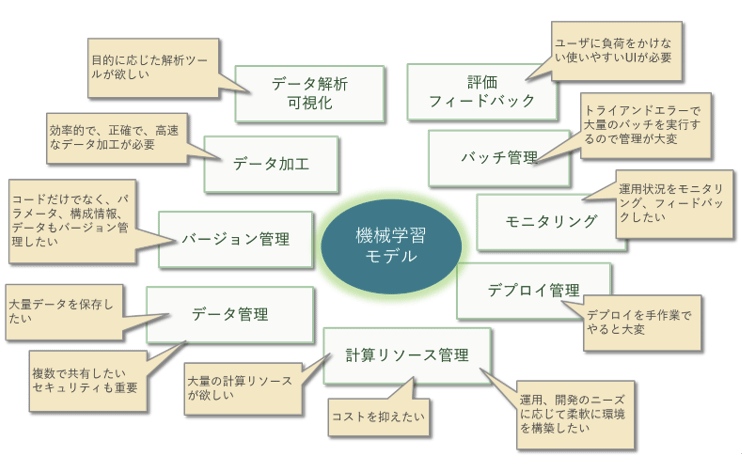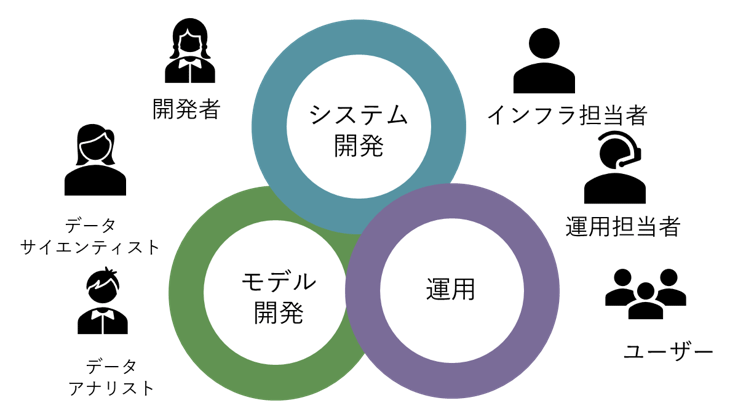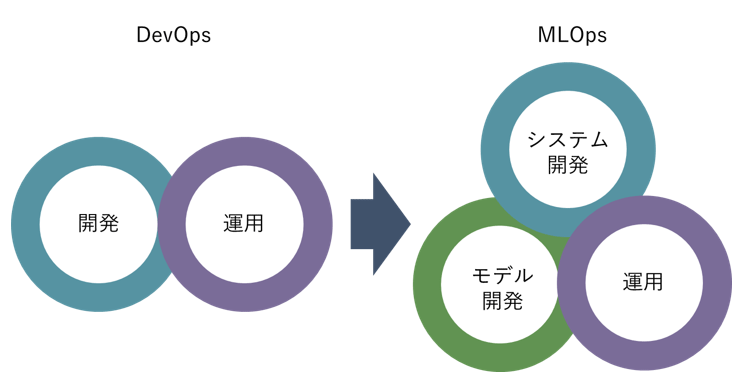




機械学習のモデル開発においては、モデルパラメータやデータ加工方法などの修正・検証を繰り返し、適切なモデルを構築していく。この工程では、開発者だけでなく、機械学習エンジニア、ユーザーなど複数の関係者が関わる。このため、それぞれにとって利用しやすい環境を提供しなければ、円滑な開発ができない。さらに、CPU、GPU、ストレージなどの計算資源も大量に消費する傾向があるため、そちらにも気を配る必要がある。
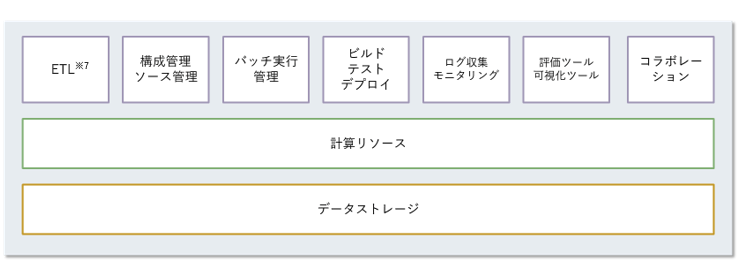
これらの課題に手作業による運用で対応することは極めて困難であり、自動化、テンプレート化、モニタリングの可視化など、システム的なアプローチが必要となる。
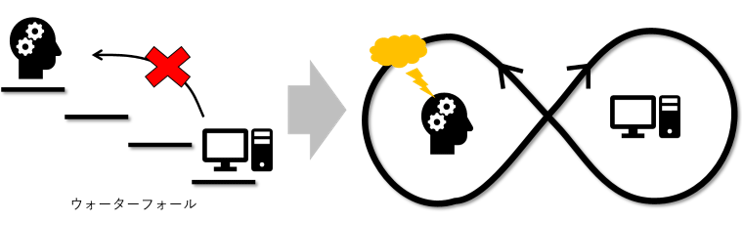
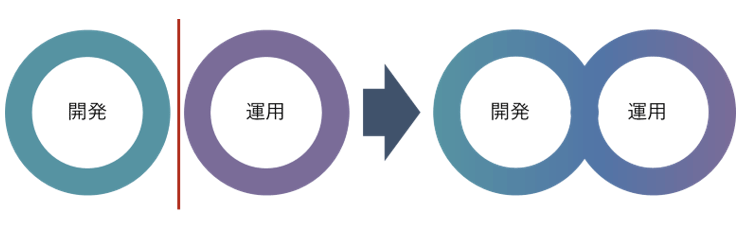
しかし、そもそも従来型のシステム開発においても、ソフトウエアの複雑さを管理するという課題にうまく対応できないジレンマを感じながら、なんとか取り組んでいるのが実情である。そこに機械学習という新たな要素が加わると、複雑度が増し、管理が破綻することが容易に予測できる。特にPoC※1から開発に進む場合、当初の開発・運用はうまくいっても、その後プロセスがうまく回らず、費用が無駄にかさんでいく、欲しいタイミングでの開発が間に合わない、といった状況もありえる。
幸い、このような状況に対していくつかの解決策が提案されており、そのための技術面およびインフラ面での準備も整ってきている。本稿では、機械学習を導入したシステム開発の課題について、その解決の方向性と具体策について紹介する。
これらの課題に手作業による運用で対応することは極めて困難であり、自動化、テンプレート化、モニタリングの可視化など、システム的なアプローチが必要となる。
しかし、そもそも従来型のシステム開発においても、ソフトウエアの複雑さを管理するという課題にうまく対応できないジレンマを感じながら、なんとか取り組んでいるのが実情である。そこに機械学習という新たな要素が加わると、複雑度が増し、管理が破綻することが容易に予測できる。特にPoC※1から開発に進む場合、当初の開発・運用はうまくいっても、その後プロセスがうまく回らず、費用が無駄にかさんでいく、欲しいタイミングでの開発が間に合わない、といった状況もありえる。
幸い、このような状況に対していくつかの解決策が提案されており、そのための技術面およびインフラ面での準備も整ってきている。本稿では、機械学習を導入したシステム開発の課題について、その解決の方向性と具体策について紹介する。