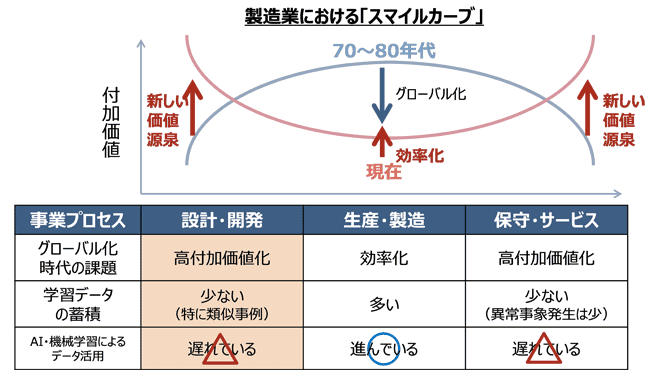




第1回のコラムで紹介した囲碁AI(Alpha Go)が人間のトップ棋士に勝利した事例に代表されるように、AIやその推論エンジンをデータから構築する機械学習のテクノロジーは急速に進化している。交通分野の自動運転車、製造分野の生産や輸送の効率化・高度化、さらには金融分野でのフィンテックなど、あらゆる産業で先を競って、このテクノロジーの応用が進められている。
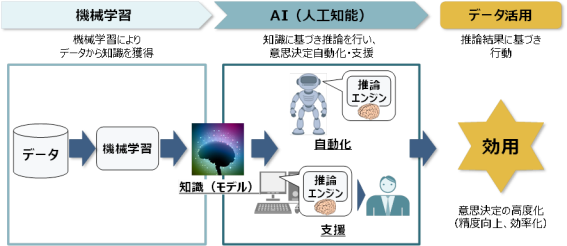
AI・機械学習によるデータ活用のフローは、図1のように大きく2つのパートに分かれる。機械学習によりデータ解析し、知識(モデル)を獲得するパートと、知識を用いてAIが推論を行い、意思決定を自動化または支援するパートだ。推論に基づき行動した結果、従来よりも効用が得られれば、AI・機械学習によるデータ活用が「成功」したといえる。成功のカギは、機械学習により事前にデータから精度のよい知識(モデル)を獲得することである。
AI・機械学習によるデータ活用のフローは、図1のように大きく2つのパートに分かれる。機械学習によりデータ解析し、知識(モデル)を獲得するパートと、知識を用いてAIが推論を行い、意思決定を自動化または支援するパートだ。推論に基づき行動した結果、従来よりも効用が得られれば、AI・機械学習によるデータ活用が「成功」したといえる。成功のカギは、機械学習により事前にデータから精度のよい知識(モデル)を獲得することである。
図1 AI・機械学習によるデータ活用