



第2回連載では、データ駆動型事業運営に転換を図るべき事業・業務として、マーケティング、リスク管理、ビジネスリソース最適化を取り上げた。今回はデータ駆動型事業の具体的な事例としてリスク管理分野への適用事例を紹介する。AIを活用した、新たなリスク管理手法の導入メリットと課題にも触れる。
大手企業各社のIR情報を見ると、以下のような事業を取り巻くリスクが散在している。
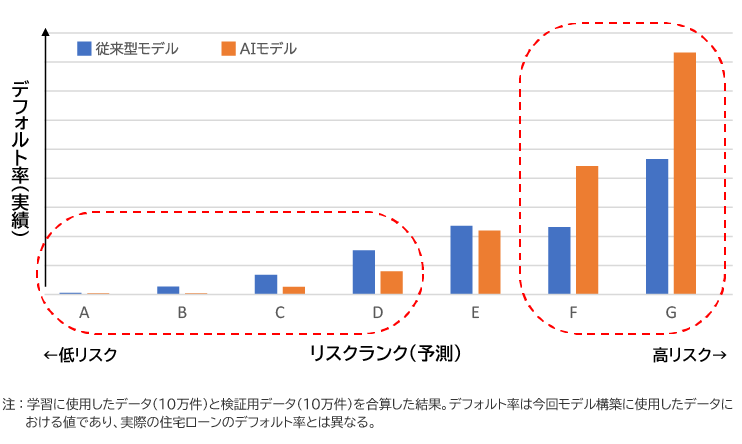
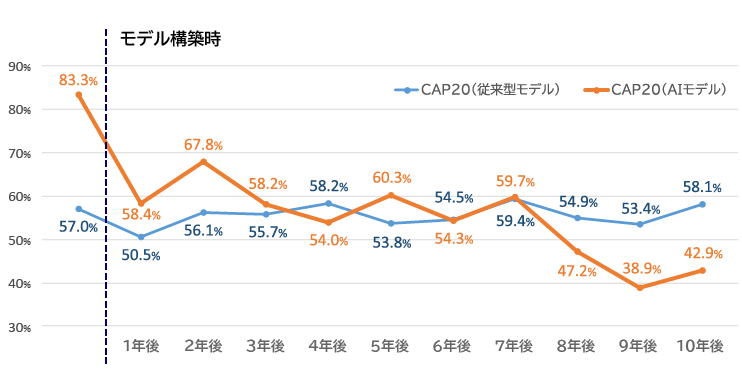
これらのリスクについて、発生確率の予測やリスクが顕在化した場合の影響把握などに対応するため、それぞれ定量化が行われてきた。リスク定量化については、以前からデータ活用が他分野と比べ進んでおり、各種リスクに応じた統計モデルや分析手法が開発されている。これらの中でも、特に進んでいるのが信用リスク評価である。
信用リスクとは、金融機関において借り手となる個人顧客や法人顧客が債務を履行できなくなる(支払いができなくなる)リスクのことである。
今回はリスク管理分野の中でも特にリスク定量化が進んでいる信用リスクを取り上げ、どのようにデータ駆動の適用が行われているかを解説する。
大手企業各社のIR情報を見ると、以下のような事業を取り巻くリスクが散在している。
- 事故・災害リスク(事業継続リスク)
- 財務リスク・信用リスク・不正リスク
- 運用リスク・システムリスク(サイバー攻撃によるリスクも含む)
- 風評リスク・法務リスク・コンプライアンスリスク
これらのリスクについて、発生確率の予測やリスクが顕在化した場合の影響把握などに対応するため、それぞれ定量化が行われてきた。リスク定量化については、以前からデータ活用が他分野と比べ進んでおり、各種リスクに応じた統計モデルや分析手法が開発されている。これらの中でも、特に進んでいるのが信用リスク評価である。
信用リスクとは、金融機関において借り手となる個人顧客や法人顧客が債務を履行できなくなる(支払いができなくなる)リスクのことである。
今回はリスク管理分野の中でも特にリスク定量化が進んでいる信用リスクを取り上げ、どのようにデータ駆動の適用が行われているかを解説する。